1. 데이터 엔지니어링이란
- 데이터 엔지니어링에 관한 다양한 사람들의 정의들
- 조직 내 다른 전문가가 데이터를 사용할 수 있도록 만드는 일련의 작업
- 데이터 엔지니어는 조직의 데이터 인프라를 구축하고 운영해 데이터 분석가와 데이터 과학자가 추가 분석을 수행할 수 있도록 준비한다.
- 데이터 엔지니어링의 유형은 SQL 중심과 빅데이터 중심으로 나뉜다.
- 데이터 엔지니어링 분야는 소프트웨어 엔지니어링에서 더 많은 요소를 가져오는 비지니스 인텔리전스와 데이터 웨어하우징의 상위집합(superset)으로 ‘빅데이터’ 분산 시스템 운영에 관한 전문화를 통합한다.
- 데이터 엔지니어링은 데이터의 이동, 조작, 관리에 관한 모든 것
- 조직 내 다른 전문가가 데이터를 사용할 수 있도록 만드는 일련의 작업
1-1. 데이터 엔지니어링 정의
- 데이터 엔지니어링
- 원시 데이터 (raw data)를 가져와 분석 및 ML 같은 다운스트림 사용 사례를 지원
- 고품질의 일관된 정보를 생성하는 시스템과 프로세스를 개발, 구현, 및 유지관리하는 작업
- 보안, 데이터 관리, 데이터 운영, 데이터 아키텍처, 오케스트레이션, 소프트웨어 엔지니어링의 교차점
- 데이터 엔지니어(DE)
- 데이터 엔지니어링 수명 주기를 관리
- 데이터 엔지니어링 수명 주기: 원천 시스템에서 데이터를 가져와 분석 or ML 사용사례에 데이터를 제공하는 과정
- 데이터 엔지니어링 수명 주기를 관리
1-2. 데이터 엔지니어링 수명 주기
- 데이터 엔지니어링 수명 주기(data engineering lifecycle)
- 데이터 자체와 데이터가 제공해야 하는 최종 목표

- 데이터 엔지니어링 수명 주기 단계
- 데이터 생성(generation)
- 데이터 저장(storage)
- 데이터 수집(ingestion)
- 데이터 변환(transformation)
- 데이터 서빙(serving)
- 데이터 엔지니어링의 드러나지 않는 요소(undercurrent)
- 보안
- 데이터 관리
- 데이터옵스
- 데이터 아키텍처
- 오케스트레이션
- 소프트웨어 엔지니어링
1-3. 데이터 엔지니어의 진화
- 1980 - 2000년: 데이터 웨어하우징에서 웹으로
- 비지니스 데이터 웨어하우스(business data warehouse)와 데이터 웨어하우스(data warehouse) 용어의 출현
- 데이터 웨어하우징(DW): 시장에서 발생하는 대량 데이터를 처리하고 지원하는 시스템
- 다수의 프로세서를 사용하는 대규모 병렬 처리 데이터베이스(MPP) 출현으로 확장성 있는 분석을 가능케 함
- 데이터 웨어하우스와 BI(Business Intelligence) 엔지니어링은 오늘날의 데이터 엔지니어링의 선구자격
- 2000s: 현대 데이터 엔지니어링의 탄생
- 90s까지 전통적 모놀리식 RDBMS와 DW는 시스템적 한계사항까지 도달함
- 차세대 시스템은 비용효율적, 확장성과 가용성, 안정성을 갖춰야 했음
- 대규모 컴퓨팅 클러스터의 출현으로 분산 연산과 분산 저장이 가능케됨 → 빅데이터 시대의 도래
- 빅데이터: 데이터의 3V (속도 velocity, 다양성 variety, 크기 volume) 특징을 띈 대규모 데이터
- 아마존의 출현
- 아마존 웹서비스(AWS)가 외부 서비스로 오픈되면서 퍼블릭 클라우드 서비스가 출현함
- 가상 하드웨어의 대여함으로써 기업들의 하드웨어, 소프트웨어 관리 리소스를 줄여줌
- 90s까지 전통적 모놀리식 RDBMS와 DW는 시스템적 한계사항까지 도달함
- 2000 - 2010s: 빅데이터 엔지니어링
- 하둡, 오픈소스 빅데이터 도구의 성숙으로 대부분 기업은 최고 수준의 기술업체와 동일한 최첨단 데이터 도구에 접근이 가능해짐
- 배치 컴퓨팅에서 이벤트 스트리밍으로의 전환 혁신이 발생함 (일/시간 단위의 비실시간성 → 실시간 분석으로 변경)
- 빅데이터 엔지니어 (big data engineer)의 탄생
- 대규모 데이터 제공을 위해 상용 하드웨어의 대규모 클러스터를 유지 관리
- 데이터 도구의 폭발적 증가가 영향을 미침
- 코드 우선 (code-first) 엔지니어링의 유행
- 빅데이터에 대한 이해도가 낮아 작은 데이터 문제에도 하둡 클러스터 등 빅데이터 도구를 사용하는 경우들이 발생
- 빅데이터 엔지니어는 복잡한 도구 유지, 관리에 큰 시간을 들이면서도 비지니스의 통찰력과 가치를 파악하는데엔 장점을 발휘하지 못함
- 단순화(simplification)로의 회귀
- 개발자들과 업체들은 빅데이터를 추상화하고 단순화하면서도 사용 가능한 방법을 찾기 시작함
- 대부분 회사들은 더이상 데이터의 사이즈에 집착하지 않고 데이터 자체를 분석해 문제를 해결하는걸 목표로 함
- 2020s: 데이터 수명 주기를 위한 엔지니어링
- 데이터 엔지니어는 기존 모놀리식 프레임워크(저수준 세부 정보) 툴에서 분산/모듈/관리/추상화 도구로 이동시키고 있다.
- 모던 데이터 스택(modern data stack): 상용 오픈 소스들 및 서드 파티 제품들의 모음
- 데이터 엔지니어링은 궁긍적 비지니스 목표를 달성하기 위해 다양한 기술을 조립하고 연결하는 상호 응용 분야로 발전하고 있음
- 데이터 엔지니어는 기존 모놀리식 프레임워크(저수준 세부 정보) 툴에서 분산/모듈/관리/추상화 도구로 이동시키고 있다.

-
- 과거와 비교해 다양한 데이터 툴들이 태동하고 있으며, 데이터 엔지니어들은 이를 회사 환경에 맞게 조립하고 연결하여 사용하고 있음
- 데이터 수명 주기 엔지니어(data lifecycle engineer)의 출현
- 추상화와 단순화를 통해 세부사항에 큰 신경을 쓰지 않게 됨
- 여전히 저수준 데이터 프로그래밍 기술을 유지하고 사용할 능력이 있어야 하지만 예전에 비해 많은 시간을 들이지 않게 됨
- 대신 보안, 데이터 관리, 데이터옵스, 데이터 아키텍처, 오케스트레이션 및 일반 데이터 수명 주기 관리 등 가치 사슬의 상위 영역까지로 역할이 확대됨
- 데이터 엔지니어의 태도 변화
- 과거에는 “가장 큰 데이터”를 잘 보유하고 관리하는 것이 목표
- 현재는 오픈 소스 프로젝트와 서비스 데이터 관리 및 통제, 사용 및 발견의 용이성, 데이터 품질 향상에 큰 관심을 기울이고 있음
- 파이프라인 설계 시 개인정보보호, 익명화, 데이터 가비지 수집 및 규정 준수에도 큰 관심과 고민을 가짐
1-4. 데이터 엔지니어링과 데이터 과학
- 데이터 엔지니어링은 데이터 과학의 업스트림 (상위역할)
- 데이터 엔지니어는 데이터 과학자가 사용할 데이터를 제공하며, 데이터 과학자는 데이터를 유용한 결과로 변환하게 됨
- 데이터 엔지니어와 데이터 과학 및 분석은 별개의 역할
- 서로를 보완하지만 다른 개념으로 바라봐야 함
- 데이터 과학 욕구 단계를 통해 데이터 엔지니어의 출현 이유를 살펴볼 수 있다.

-
- 기존 데이터 과학자(DS)는 ML 모델 구축 및 튜닝에 집중하고 싶지만, 실제론 70-80%의 시간을 계층 구조의 하위 부분(데이터 수집, 정리, 처리)에 시간을 사용하는 것으로 추정됨
- DS는 상용 제품 수준의 데이터 시스템을 처리하는 엔지니어링 훈련을 받는 경우가 적은데도 전처리 작업을 수행해야 하는 경우가 많다.
- 이상적 환경에서 DS는 분석, 실험 및 ML 튜닝같은 피라미드 최상위 계층에 90% 이상의 시간을 할애해야 한다.
- DE가 계층 구조 최하단 작업에 집중한다면 DS가 더 의미있는 활동을 할 수 있도록 지원할 수 있을 것이다.
2. 데이터 엔지니어링 기술과 활동
- 데이터 엔지니어링에 요구되는 기술역량(skill set)
- 데이터 도구들을 평가하는 방법
- 데이터 엔지니어링 수명 주기 전반에 도구들이 어떻게 조합되는지에 대한 이해도
- 원천 시스템에서 데이터가 어떻게 생성되는지에 대한 파악
- 데이터 처리, 선별 후 DS가 어떻게 소비하고 가치를 창출하는지 과정을 파악
- 가변적 요소를 처리하고 비용, 민첩성, 확장성, 단순성, 재사용성, 상호 운용성을 비교하며 최적화를 수행
- 여러 단순하고 추상화된 데이터 도구들을 조합해 민첩한 데이터 아키텍처를 구축할 수 있는 능력
- 기존 이해 관계자의 주업무를 이해해서 적절한 기능적 이해를 통해 최선의 서비스를 제공
2-1. 데이터 성숙도와 데이터 엔지니어
- 데이터 성숙도(data maturity): 조직 전체에 걸쳐 더 높은 데이터 활용률(utilization), 기능(capability), 통합(integration)을 통해 나아가는 과정
- 데이터 성숙도는 기업의 규모와는 상관없이 기업이 데이터 경쟁 우위를 얼마나 중요시 하는지로 결정됨
- 이 책에서는 데이터 성숙도 모델 (DMM, data management maturity)을 단순화해 아래 3단계로 표현한다.
- 데이터 시작하기
- 데이터 확장하기
- 데이터 선도하기
1단계: 데이터 시작하기
데이터를 시작하는 기업이 있는 단계
- 데이터 엔지니어는 DS나 소프트웨어 엔지니어 등 여러가지 모두를 수행하는 제너럴리스트임
- 목표는 빠르게 움직여서 견인력을 얻고 부가가치를 창출하는 것
- 시작단계부터 ML에 뛰어드는 것은 비추함
- DE는 아래 사항에 중점을 둬야 함
- 기업의 목표를 지원하는 데이터 아키텍처를 정의하고 설계
- 데이터 아키텍처 내에서 작동할 데이터를 확인하고 검수
- 견고한 데이터 기반을 구축
- 데이터 시작하기 단계의 DE에게 주는 팁
- 기술 부채를 줄일 계획을 세워야 함
- 내부에서만 작업하지 말고 다른 부서 사람들과도 대화를 해라
- 역할과 관련없는 과중한 업무를 감당하지 마라
- 불필요한 기술 복잡성에 얽매이지 마라
- 경쟁 우위를 창출할 수 있는 경우만 맞춤형 솔루션과 코드를 구현해라
2단계: 데이터 확장하기
어느정도 프로세스를 갖춘 기업으로 임시적으로 데이터 요청을 하지 않고 공식적인 데이터 요청 관행 프로세스가 존재하는 기업
- 확장성 있는 데이터 아키텍처 구축 및 데이터 중심의 기업으로의 도모를 계획해야 함
- DE의 목표
- 공식적 데이터 관행 수립
- 확장성 있고 견고한 데이터 아키텍처 구축
- 데브옵스 및 데이터옵스 관행 채택
- ML 지원 시스템 구축
- 과중한 업무를 피하고 경쟁우위를 확보할 때만 커스터마이징
- DE가 살펴볼 문제점들
- 모든 기술적 의사결정은 고객에게 제공되는 가치에 따라 판단되야 한다.
- 무조건 최첨단 기술이라고 좋은게 아님. 최첨단 기술은 들이는 시간과 에너지에 비해 좋은 output이 나오지 못할 가능성
- 팀의 처리량 확장을 위해서는 배포와 관리가 쉬운 솔루션에 집중해야 함
- 데이터의 실질적 유용성에 대해 다른팀과 소통하고 타팀에 데이터 사용과 활용법에 대한 교육이 필요함
- 모든 기술적 의사결정은 고객에게 제공되는 가치에 따라 판단되야 한다.
3단계: 데이터 선도하기
데이터 중심의 기업으로 DE의 자동화된 파이프라인과 시스템으로 직원들은 셀프서비스 분석과 ML 수행이 가능함
- DE의 작업 목표
- 이전 단계 목표점들을 계속해서 고도화하고 구축함
- 새로운 데이터의 매끄러운 배포와 사용을 위한 자동화 구축
- 데이터 관리 및 데이터 옵스 등 데이터의 “기업적” 측면에 집중
- 데이터 관리에는 데이터 거버넌스와 품질 관리도 포함됨
- 데이터 카탈로그, 데이터 계보 도구(data lineage), 메타데이터 관리 시스템을 포함해 데이터를 조직 전체에 노출하고 전파하는 도구를 배포
- ML 엔지니어, 데이터분석가, 소프트웨어 엔지니어 등과 효율적인 협업
- 사람들과 협업하고 토론할 수 있는 커뮤니티 환경 구축
- DE가 살펴볼 문제점들
- 현재 상태에 안주하지 마라. 항상 유지보수 및 개선에 집중해야 한다.
- 통일되지 않은 기술의 산만함은 오히려 위협요소이다. 경쟁 우위를 제공하는 경우에만 직접 구축한 기술을 활용해라.
2-2. 데이터 엔지니어의 배경과 기술
DE는 데이터와 기술 모두를 이해해야 한다.
- 데이터 측면에선 데이터 관리의 다양한 모범사례를 이해
- 기술 측면에선 데이터 엔지니어가 사용할 도구들의 다양한 옵션, 상호작용과 상충관계를 이해해야 함
- 소프트웨어 엔지니어링, 데이터 옵스, 데이터 아키텍처에 대한 이해 필요
2-3. 비지니스 책임
거시적 책임은 데이터 엔지니어 뿐만 아니라 데이터와 기술 분야 모든 종사자들에게 중요한 문제
- 비기술자 및 기술자와의 커뮤니케이션 방법 파악
- 커뮤니케이션이 핵심임
- 비지니스 요건과 제품 요건을 살펴보고 수집하는 방법 이해
- 구축할 방향을 파악하고 이해관계자가 이에 동의하는지 확인
- 애자일, 데브옵스, 데이터옵스 문화에 대한 이해
- 비용 관리
- 최대한 절감된 비용으로 동일한 가치를 누리도록
- 지속적 학습
- 흐름에 뒤쳐지지 않고 학습할 필요성
성공적인 DE는 전체의 큰 그림을 이해하고 비지니스 가치를 극대화할 방법을 파악해야 한다.
- 데이터 팀은 다른 이해관계자와 커뮤니케이션을 바탕으로 성공하는 경우가 많다.
- 기술만으로 성공하는 경우는 거의없다.
2-4. 기술 책임
- 성능과 비용을 효율적으로 최적화하는 아키텍처 구축방법을 이해해야 한다.
- 아키텍처와 구성 기술은 데이터 엔지니어링 수명 주기를 지원하는 구성요소임
- 데이터 엔지니어는 상용 제품 수준의 소프트웨어 엔지니어링 기술을 가져야 함
- 코드베이스의 상세한 아키텍처를 깊게 들여다 볼 수 있는 기술을 가지는게 필요
- 특정 기술 요구 사항 발생 시 기업에 기술적 우위를 제공할 수 있음
- 실제 상용 제품 수준 코드를 작성할 능력이 없으면 어려움을 겪을 것
- SQL, 파이썬, 자바, 스칼라, JVM(자바가상머신), 배시 등에 대한 이해가 필요
- R, js, 고, 러스트, C/C++, 줄리아 등 보조적인 프로그래밍 언어에 대한 이해가 필요할 수 있음 (기업의 주언어에 따라 달라짐).
- 유능한 데이터 엔지니어는 SQL에 매우 익숙해져야 함
- 스파크, 프랑크 등 프레임 워크 내에서나 오케스트레이션을 통한 여러 도구 결합이 발생할 경우, SQL을 다른 작업과 함께 구성하는데 필요한 전문 지식 습득이 필요함
- 숙련된 경우 SQL이 작업에 적합하지 않은 케이스들을 인식할 시, 적절한 대안을 제시하고 코드화 할 수 있음
- 기본에 충실하면서도 분야의 변화 방향을 빠르게 캐치해야 함
- 지속적인 개발에 관심을 기울여야 함
- 새로운 기술이 데이터 엔지니어링 수명 주기에 어떤 도움을 줄 수 있는지 이해할 필요
2-5. A에서 B로 이어지는 데이터 엔지니어링 역할의 연속성
- 기업의 데이터 성숙도에 따라 데이터 엔지니어는 두가지 유형으로 나뉨
- A형 데이터 엔지니어 (Abstraction, 추상화)
- 데이터 아키텍처를 최대한 추상적이고 단순하게 유지해 시간 낭비를 피함
- 과중한 작업을 피하고 기성제품, 관리형 서비스와 도구들을 이용해 데이터 엔지니어링 수명 주기를 관리
- 보통 데이터 성숙도 수준과 상관 없이 산업 전반에 걸쳐 다양한 회사에서 근무
- B형 데이터 엔지니어 (Build, 구축)
- 기업의 핵심 역량과 경쟁 우위를 확장
- 활용할 데이터 도구와 시스템을 구축
- 보통 2단계나 3단계 회사에서 근무하거나 초기 데이터가 독특해서 맞춤형 데이터 도구가 필요한 회사에서 근무
- 보통 A형 데이터 엔지니어가 기반 확립을 위해 먼저 채용되고, B형 데이터 엔지니어는 후에 사내에서 교육하거나 인재를 고용함
- 두 유형의 인재가 모두 같은 사람일수도 있음
3. 조직 내 데이터 엔지니어
3-1. 내부 vs 외부 대면 데이터 엔지니어
- 서비스 사용 사례에 따라 데이터 엔지니어 주요 업무는 다음과 같이 나뉨
- 외부 대면
- 내부 대면
- 혼합형
- 외부 대면 데이터 엔지니어 (external-facing)
- 외부용 애플리케이션 사용자와 연계함.
- 보통 IoT, SNS, E-commerce 플랫폼 사용자
- 애플리케이션 발생 트랜젝션 및 이벤트 데이터를 수집, 저장, 처리 시스템을 설계, 구축, 관리함
- 외부용 애플리케이션 사용자와 연계함.
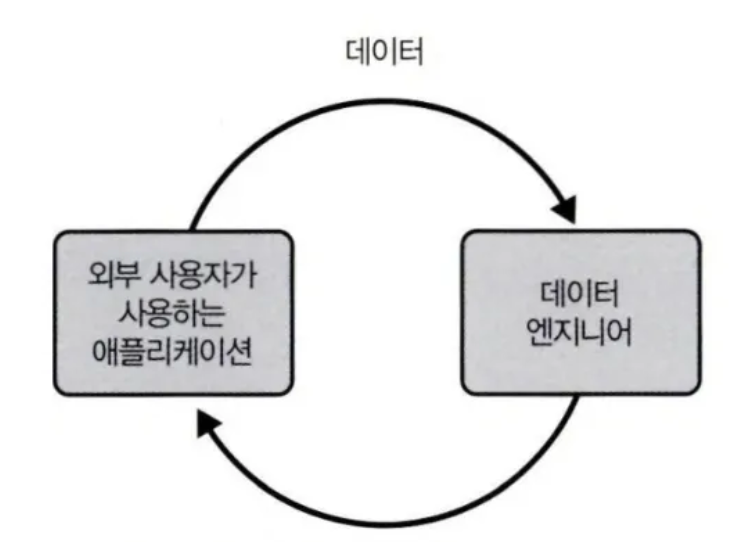
- 외부 대면 DE가 구축한 시스템은 애플리케이션과 데이터 파이프라인간 피드백 루프를 가짐
- 외부 대면 시스템의 이슈
- 내부 대면 시스템보다 훨씬 더 큰 동시성 부하를 처리하는 경우가 많다.
- 외부대면 DE는 사용자가 실행할 수 있는 쿼리에 훨씬 엄격한 제한을 둬서 사용자가 인프라에 미치는 영향을 최소화해야 한다.
- 쿼리되는 데이터가 많은 고객 데이터가 단일 테이블에 저장되는 멀티테넌트(multitenant) 경우는 더 신경써야 함.
2. 내부 대면 데이터 엔지니어 (internal-facing)

- 비지니스 및 내부 이해관계자 요구사항에 집중
- BI 대시보드, 보고서, 비지니스 프로세스, 데이터 과학, ML 모델용 데이터 파이프라인(ETL), DW생성 및 유지 보수 등이 포함
- 외부 대면업무와 내부 대면 업무는 혼합될 수 있음
- 내부 대면 데이터는 일반적으로 외부 대면 데이터의 근간(raw data)임.
3-2. 데이터 엔지니어와 기타 기술 역할
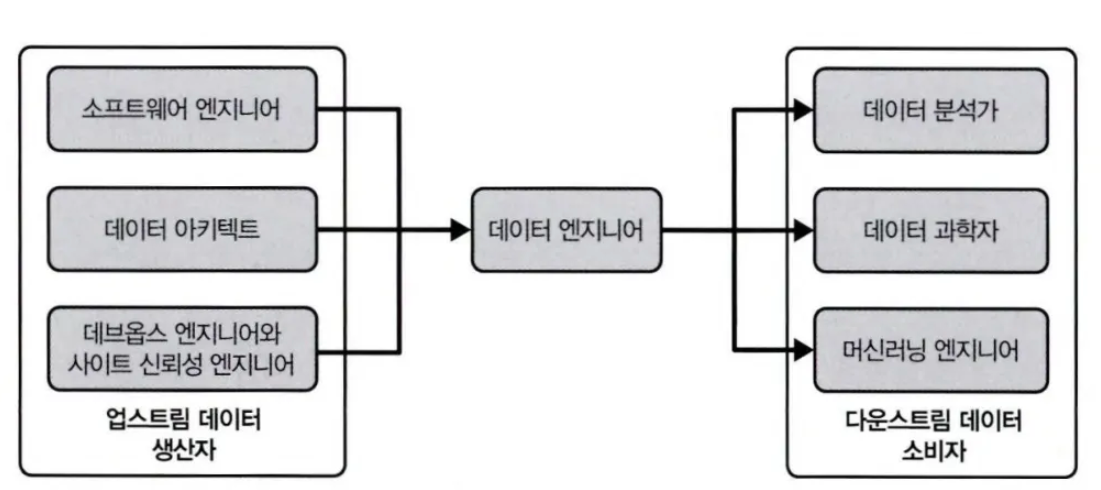
- 데이터 엔지니어는 데이터 생산자(data producer)와 데이터 소비자(data consumer) 사이의 허브 역할
- 데이터 생산자 (업스트림 이해관계자)
- 소프트웨어 엔지니어
- 데이터 아키텍트
- 데브옵스 엔지니어 or 사이트 신뢰성 엔지니어(SRE)
- 데이터 소비자 (다운스트림 이해관계자)
- 데이터 분석가
- 데이터 과학자
- ML 엔지니어
3-3. 데이터 엔지니어와 비지니스 리더십
- 기업 내 최고 경영진, 그리고 타직군과 데이터간 관계를 설명한 챕터
- 최고경영진 부류
- 최고경영자(CEO)
- 최고 정보 책임자(CIO)
- 최고 기술 책임자(CTO)
- 최고 데이터 책임자(CDO)
- 최고 분석 책임자(CAO)
- 최고 알고리즘 책임자(CAO-2)
- 그외 직군과의 소통
- 프로젝트 매니저
- 제품 관리자
- 기타 관리 역할
'Study > Data' 카테고리의 다른 글
| [견고한 데이터 엔지니어링] 03장. 우수한 데이터 아키텍처 설계 (0) | 2025.04.06 |
|---|---|
| [견고한 데이터 엔지니어링] 02장. 데이터 엔지니어링 수명 주기 (0) | 2025.04.04 |