CS230 Deep Learning
Lecture 2. Deep Learing Intuition
이번 강의는 제목처럼 딥러닝에 대한 직관을 끌어내려 하였다.
수식도 일부 있었지만, 주요점은 어떤 문제를 풀 때 어떻게 딥러닝을 적용하는 것이 좋은가? 에 초점을 두었다 생각한다.
주요 슬라이드별로 내용을 정리하려 한다.
Lecture 2 소개

이번 강의는 AI project를 진행할 때 의사결정을 어떻게 할 것인지를 주로 다루었다.
특히 아래의 4가지 How To에 대해 설명하였다.
- Collect: 데이터를 어떻게 모을 것인가?
- Label: 데이터의 라벨링을 어떻게 할 것인가?
- Architecture: 모델링 구조를 어떻게 설계할 것인가?
- Optimize: 해당 모델을 어떻게 최적화할 것인가?
AI 모델의 학습 과정
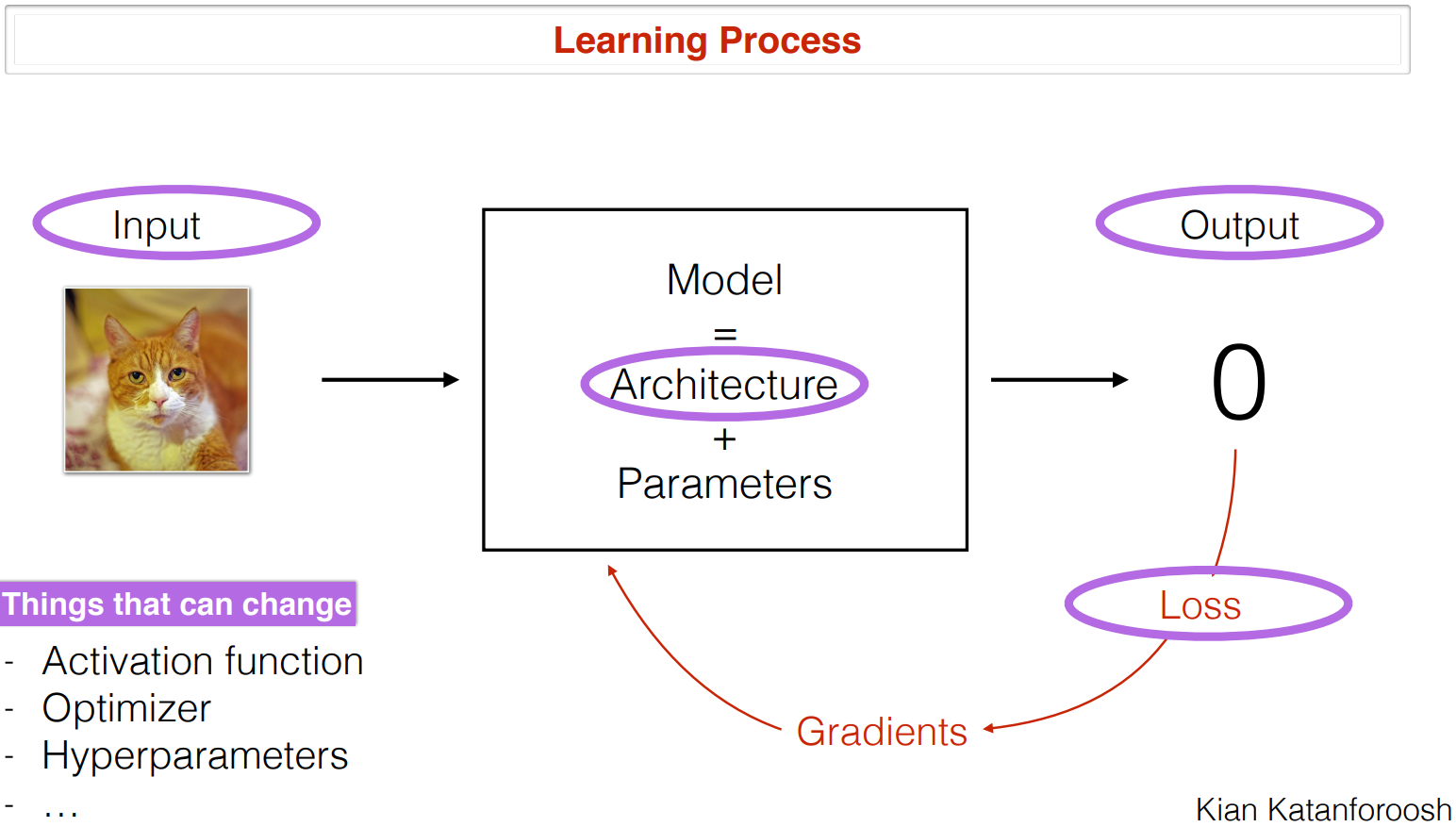
먼저 AI 학습 과정을 살펴보면 다음과 같다.
1. 어떤 문제가 주어진다. 사용자는 이 문제에서 특정 Output을 예측하고 싶다.
2. 모델링을 설계한다. 그리고 문제와 관련된 Input들이 모델로 들어간다.
- 모델은 파라미터들로 구성된 Architecture라 볼 수 있다.
- 여기서 Architecture는 사용자가 선택하는 모델 종류, 구조이다.
- Parameters 는 모델이 학습되면서 스스로 찾아가는 값이다.
3. 모델의 파라미터는 예측한 결과와 실제 결과 값의 차이(Loss)를 통해 학습된다.
- 파라미터는 보통 Loss function의 gradients 값을 이용해 Loss를 줄이는 방향으로 학습된다.
여기서 사용자는 더 좋은 모델 학습을 위해 모델의 여러 구조를 변경해볼 수 있다.
- 활성화 함수 (Activation function)
- 옵티마이저 (Optimizer)
- 초매개변수 (Hyperparameter)
그러면 문제가 주어졌을 때 사용자들은 어떻게 이 과정들을 수행할까?
Multi-class 문제 예시

1. 문제 설정
- 이미지에 있는 동물이 무엇인지 예측하는 문제라고 하자.
- 이미지에는 여러 동물들이 존재할 수 있으니 Multi-class를 예측하는 문제로 설정한다.
2. 모델링 설계와 입력 데이터
- Multi-class이니 예측할 동물의 수만큼 output을 뱉게끔 설정한다. Output은 각 동물일 확률을 나타낸다.
- 모델은 MLP (Multi-Layer Perceptron)로 설정하였다.
- 모델 구조에 적합하게 입력 이미지를 변환해준다. 2차원 구조의 이미지를 하나의 벡터로 flatten하였다.
- 모델 학습에 적합하게 이미지의 각 벡터값을 255로 나누어서 정규화 해준다.
3. 학습을 위한 라벨 설정
- Output 라벨은 어떻게 설정할 것인지가 중요하다. 아래 두가지 후보가 있을 수 있다.
- One-hot vector: 이미지에 존재하는 특정 물체의 값을 1로, 나머지는 0으로 설정하는 방법
- Multi-hot vector: 이미지에 존재하는 모든 물체의 값을 1로, 없는 물체는 0으로 설정
- 이미지에는 하나의 동물만 있다는 가정이 없기 때문에 Multi-hot vector로 이미지에 존재하는 동물들을 라벨링한다.
위와 같이 AI 학습 과정을 살펴볼 수 있었다.
이미지 학습에서의 딥러닝

한편 딥러닝 모델은 이미지 학습에 효과적이라고 알려져 있다.
이미지는 특히 복잡한(Complex) 입력 데이터로 알려져 있었고, 고전적인 컴퓨터 비전 연구에서는 좋은 성능을 내기 어려웠다.
하지만 딥러닝 모델들은 이미지의 특징들을 잘 학습하여 좋은 성능을 내는 것을 증명하였는데, 이유는 다음과 같다.
- 딥러닝 모델은 예측을 위한 여러 층으로 구성되어 있다.
- 초기 층들은 이미지의 아주 작은 특징들을 학습한다. 이 특징들은 pixel 단위로 이미지의 edges나 낮은 레벨의 특징들을 추출한다.
- 깊은 층으로 들어갈 수록 낮은 층들의 low level 특징들을 추출하여 더 높은 레벨의 특징들을 학습한다. 낮은 층의 정보들이 깊은 층에서 이미지의 전반적 특징들을 추출하는 것을 가능하게 한다.
아래에서는 이미지를 이용한 딥러닝 모델을 학습하는 예시들을 더 살펴보자.
Case Study 1: 낮과 밤 예측 문제

먼저 사진을 보고 낮인지, 밤인지 예측하는 문제가 주어졌다고 한다.
그러면 AI 모델러는 크게 다음의 내용들을 고민하고, 결정하게 될 것이다.
1. Data
- 데이터 크기
- 데이터를 얼마나 수집할 것인지는 푸는 문제의 복잡도에 큰 영향을 받는다. 이 문제는 덜 복잡한 문제이기 때문에 10,000개 정도의 데이터도 충분할 것으로 보인다.
- 성능 점검
- 모델이 잘 예측하는지 확인하기 위해서는 성능 평가가 필요하다. 이를 위해서 기존 데이터를 train/dev/test 또는 train/test로 나누어서 모델을 학습하고 성능을 평가한다.
- test나 val/test의 데이터 사이즈를 무조건 80%, 나머지 20% 등 비율로 나눌 필요는 없다. 데이터의 크기, 문제의 복잡성 등을 고려해 적절한 데이터 분할 비율을 설정한다.
- 한편 데이터를 나눌 때 종속변수(y)의 비율에 bias가 생기지 않도록 주의하여야 한다. 종속변수 Class의 balance를 잘 나누어서 학습과 평가를 하여야 주어진 모델을 잘 학습하고 평가할 수 있다.
2. Input
- 본 데이터는 낮과 밤을 예측하는 이미지 데이터가 입력으로 사용된다.
- 이미지의 화질은 어느정도로 하는 것이 적절할까? 고화질의 이미지가 좋아보이지만, 이는 학습 시간과 컴퓨팅 자원을 많이 요구하게 된다. 모델링의 성능에 큰 차이가 없다면 화질을 낮추어서 효율적으로 학습하는 것이 바람직하다.
- 해당 문제에서는 64 x 64의 RGB값을 가진 이미지 정도면 충분히 잘 예측할 것으로 보인다.
3. Output
- 낮인지 (0), 밤인지 (1)를 예측하기 위해 binary 변수를 사용한다.
- activation function으로는 모든 값을 0 ~ 1로 변환하는 sigmoid 함수를 사용한다.
4. Architecture
- 간단한 문제라 층이 얕은 CNN 모델로 잘 학습될 것으로 보인다.
5. Loss
- 모델 학습을 위한 Loss function으로는 Binary cross entropy를 사용한다.
Case Study 2: 얼굴 인식 문제

다음으로 어떤 기관에서 사람의 이미지를 받았을 때 이 사람이 기관의 회원인지 확인하는 문제를 보자.
Data는 각 회원들의 사진이고, 입력 이미지로는 꽤 고화질의 정면사진이 요구될 것이다.
그리고 결과는 이 사람이 회원인지 (1), 아닌지 (0)를 binary로 나타내면 된다.
다음으로 모델 구조는 어떻게 하면 좋을까?
- One-hot으로 특정 사람인지 여부를 표현하면 아래의 문제점들이 생길 수 있다.
- 새로운 회원이 생길 때 마다 그 사람의 정보를 포함하기 위해 모델을 다시 학습해야된다.
- 특히 회원이 특정 주기마다 바뀌는 경우에는 비효율적이다.
- 회원의 규모가 큰 경우 결과 dimension이 굉장히 클 수 있다.
- 따라서 예시에서는 회원들의 이미지를 딥러닝 모델에서 특정 벡터로 먼저 인코딩한다. 벡터 값들은 이미지의 주요 정보들을 함축하고 있다.
- 새로운 입력이 들어오면 해당 이미지도 딥러닝 모델을 통해 특정 벡터로 인코딩한다. 그리고 기존 회원들간의 거리를 계산한다.
- 거리의 최솟값이 특정 임계값(threshold) 이하인 경우는 회원으로 분류하고, 아닐 경우는 비회원으로 구분한다.

그러면 위 문제에서 학습은 어떻게 하는게 좋을까?
인코딩을 위해서 triplet learning을 이용할 수 있다.
- 우리는 인코딩 벡터간 거리가 같은 사람에 대해서는 작게, 다른 사람에 대해서는 멀게 하고싶다.
- triplet은 이미지 3개를 입력하여 학습할 수 있다. 이미지는 다음과 같이 나뉜다.
- Anchor: 기준 이미지
- Positive: Anchor와 동일한 사람의 이미지
- Negative: Anchor와 다른 사람의 이미지
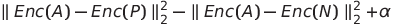
위 이미지 3개를 입력하여 같은 사람간의 거리는 작게하고, 다른 사람간의 거리는 멀게끔 Loss function을 위 같이 구성하면 된다.
- 여기서 Enc(A)는 Anchor 이미지의 인코딩 벡터, Enc(P)는 Postive 이미지의 인코딩 벡터, Enc(N)은 Negative 이미지의 인코딩 벡터이다.
- 모델은 기본적으로 Loss function을 줄이는 방식으로 학습된다.
- 따라서 Loss function에서 첫번째 term은 Anchor와 Positive 이미지간 거리가 작게끔, 두번째 term은 Anchor와 Negative 이미지간 거리가 크게끔 모델이 학습하게 한다.
- 여기서 3번째 term에 알파(α)를 붙인다. 이는 Loss 결과가 0이 나오면 학습되지 않는 것을 방지하기 위해서 붙이는 것으로 network가 특정 지점에서 안정화 되는 것을 방지한다.
Case Study 3: 이미지 스타일 생성 문제

다음 예시는 이미지 style을 변경하는 문제에 대해서 다룬다.
이미지를 넣었을 때 그 이미지의 내용은 그대로 유지하면서 스타일만 변경하는 것이다.
예를 들어 도시 사진을 넣었을 때 도시의 배경은 유지하면서 피카소풍의 스타일로 변경할 수 있다.
이 문제는 처음부터 모델을 학습하는거 보다는 parameter가 잘 학습돼 있는 사전학습 모델(pre-trained model)을 사용하는게 효율적이다.
여기서 ImageNet을 사용했는데, 다양한 종류의 이미지들의 정보를 잘 학습했기 때문에 모델 파라미터들이 이미지를 잘표현할 것이기 때문이다.
이 모델을 이용해 도시 사진의 내용을 컨텐츠 벡터 (Content_C)로 분리하고, 피카소 풍의 이미지에서는 스타일을 스타일 벡터 (Style_S)로 분리한다.

다음으로 분리된 벡터를 이용해 이미지를 생성한다.
이미지는 실제 이미지를 제시할 수도 있으나 학습에 편향을 제거하기 위해서 여기서는 noise 값으로 학습하였다.
해당 노이즈도 동일한 딥러닝 모델을 이용해서 노이즈의 컨텐츠 벡터(Content_G)와 스타일 벡터(Style_G)를 추출한다.

이를 이용해 Loss function을 계산한다.
그리고 기존 도시의 배경 내용 벡터(Content_C)와 생성된 이미지의 내용 벡터(Content_G), 그리고 피카소풍의 스타일(Style_S) 벡터와 생성된 이미지의 스타일 벡터(Style_G)의 차이를 이용해 노이즈의 Loss를 줄이는 방식으로 학습해나간다.
여기서 주의할 점은 Loss function을 이용해 노이즈를 도시 이미지의 내용과 피카소 이미지의 스타일을 학습하는 것이지, 이 Loss function이 딥러닝 모델의 파라미터를 학습하지는 않는다.
즉, pre-trained model의 파라미터 값은 그대로 유지(freezing)하면서 노이즈 이미지만 학습하는 것이다.
이렇게 학습을 2,000번 정도하면 도시의 내용은 유지하면서 피카소 풍의 스타일로 변경된 이미지가 생성된다.
Case Study 4: 특정 단어 인식 문제

다음 예시 문제는 10초 짜리 음성에서 "activate"라는 단어가 출현하는지를 탐지하는 문제이다.
이 문제는 애플의 시리, 삼성의 빅스비 등 기기의 AI 봇을 호출하는 경우에 해당한다.
1, 2. Data, Input
- 데이터는 10초짜리 오디오 클립이며, 여러가지 억양, 남녀 차이, 톤 등 차이를 고려해 데이터를 수집해야 한다.
3. Output
- 10초짜리 클립 하나의 결과를 단순히 단어의 미출현(0)과 출현(1)로 분류하는 것보다는 각 부분을 step size로 나누어서 이 부분에서 "activate"라는 단어가 출현했는지 파악하는 것이 더 유용하다.
- 모델은 각 부분마다 단어 출현 여부를 판단하기 때문에 좀 더 activate라는 단어를 맞추는 문제라는 것을 빨리 학습한다.
- 각 부분마다 출현 여부를 학습하기 때문에 학습할 데이터 양을 늘릴 수 있다.
- 특정 단어 출현 직전 보다는 직후를 출현(1)으로 설정할 것
- 사람도 단어가 출현한걸 듣고 나서 그 단어를 말한걸 알지, 그전에는 알 수 없음
- 특정 단어 출현 지점만 1로 두지 말고, 그 뒤에 0.5초 정도 여유 구간을 다 1로 두는 것이 적합할 수 있다.
- 10초 오디오 클립에서 특정 단어 출현의 비중이 매우 적을 것이기 때문에 class-imbalanced 문제로 학습이 잘 안될 수 있기 때문
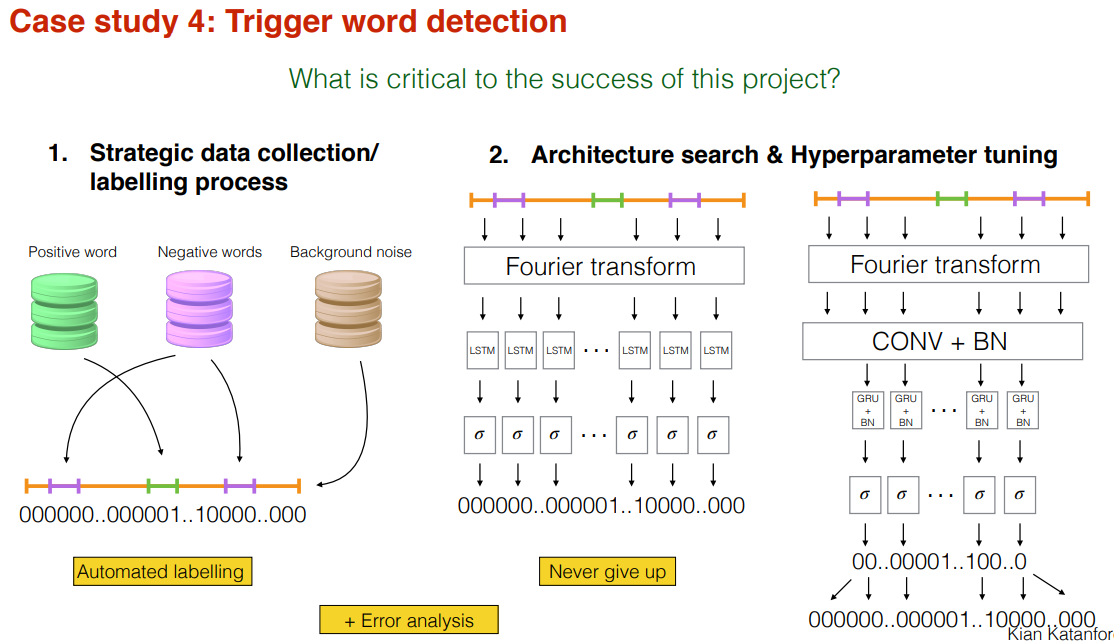
이 프로젝트에는 다양한 전략을 사용할 수 있다.
1. Data Collection / Labelling
- 한편 음성을 녹음하고 Output에서 제시한 방법으로 라벨링하기는 매우 어렵다. 따라서 데이터 수집과 라벨링 방식을 자동화할 필요가 있다.
- 이는 "activate" 단어가 녹음된 Positive word 음성과 이외의 단어가 녹음된 Negative word 음성, 잡음이 녹음된 Background noise를 이용한다.
- Background noise를 배경으로 10초간 깔고, 그 안에 positive word와 Negative word 음성을 무작위로 삽입한다. 물론 겹치지는 않게 넣는다(not overlapping). 그리고 Positive word 출현마다 1로 라벨링을 한다.
2. 모델링 구조, 하이퍼파라미터 튜닝
- 모델링 전체를 RNN 형식의 sequence 모델로 학습하는 것은 학습에 시간이 많이 소요될 수 있다.
- 따라서 Convolution + Batch 형식의 모델로 압축을 하고, 그 압축된 Sequence를 예측하는 것이 시간 소요를 줄이는데 도움이 될 수 있다.
- 한편 압축되었기 때문에 결과는 다시 span해준다.
그외 이야기

Kian은 이미지 검출 알고리즘 중 하나인 YOLO의 Loss function을 가장 아름다운 손실 함수라 생각한다.
여기서 Loss function만으로 설명하기에는 강의 주제에서 벗어나는거 같아,
YOLO에 대해서는 향후에 정리할 기회가 있으면 따로 포스팅 할 예정이다.
후기
확실히 수업이 어떤 알고리즘들의 원리를 설명하기 보다는
어떤 문제가 주어졌을 때 분석자가 어떤 방식으로, 왜 그렇게 접근하는지를 다룬 수업이었다.
딥러닝을 잘 모르는 경우에는 조금 어려울 수 있을거 같으나 핵심 직관들은 잘 캐치할 수 있도록 설명해주신거 같다.
'Study > 딥러닝' 카테고리의 다른 글
| [CS230] Deep Learning Lecture 6 Deep Learning Project Strategy (0) | 2022.09.21 |
|---|---|
| [CS230] Deep Learing Lecture 5 AI + Healthcare (0) | 2022.09.20 |
| [CS230] Deep Learning Lecture 4 Adversarial Attacks / GANs (1) | 2022.09.20 |
| [CS230] Deep Learning Lecture 3 Full-Cycle Deep Learing Projects (2) | 2022.09.19 |
| [CS230] Deep Learing Lecture 1 Class Introduction and Logistics (0) | 2022.09.18 |