보통 코드를 실행하면 작성된 순서대로 순차적으로 처리된다.
그런데 코드를 작성하다보면 특정 행위를 반복하는 코드를 작성할 때가 많다.
간단한 반복행위는 for나 while로 순차적으로 처리해도 문제가 없는데, 연산량이 커지면 시간이 그만큼 많이 소요가 된다.
이 때 코드 병렬화를 진행하면 연산 시간을 많이 줄일 수 있다.
간략한 Ray 라이브러리 소개
Ray는 작성된 코드를 병렬화 해주는 라이브러리이다.
그럼 병렬화는 어떻게 하는걸까?

이는 CPU의 코어와 관련이 깊다.
CPU는 일을 하는 회사, 코어는 CPU 속 일하는 일꾼의 수로 보면 이해하기 쉬운데, 기술이 발전하면서 CPU속 코어의 수도 많아지고 있다.
보통 코드를 돌리면 단일 코어에서 코드가 작성된 순서대로 실행된다. 이 코드 실행은 하나의 일(단일 쓰레드)이라고 이해하면 쉽다.
한편 Ray를 이용해서 반복되는 코드를 작성하면, Ray 라이브러리는 반복되는 내용을 여러 일(멀티 쓰레드)로 나눈다.
그리고 나눠진 내용들을 CPU의 코어들에 분배해서 코드를 병렬적으로 처리할 수 있는 것이다.
Ray에 대한 자세한 설명은 Ray 공식 Document에서 확인할 수 있다.
Ray 라이브러리 Setup
먼저 Ray 라이브러리를 아래와 같이 설치해준다.
pip install ray
다음으로 파이썬에서 ray 라이브러리를 불러오고, ray를 실행한다.
import ray
# Start ray
ray.init(ignore_reinit_error=True, object_store_memory = 1e+9, num_cpus = os.cpu_count()-3, include_dashboard = False)
여기서 ray를 시작할 때의 옵션들은 다음을 의미한다.
- ignore_reinit_error: ray 실행 후 다시 init 함수를 호출하면 에러메시지가 출력된다. 이 옵션을 True로 준 경우는 재실행했을 때 이를 무시하여 오류를 발생시키지 않게한다.
- object_store_memory: ray는 코드를 병렬처리 하기 때문에 메모리를 그만큼 더 많이 사용한다. 이 메모리에 저장할 양은 보통 default되어 있는데, 이를 명시적으로 변경해주는 옵션이다. 보통 저장할 메모리양이 부족하다고 에러메시지가 출력되는 경우 변경해주도록 하자.
- num_cpus: CPU 코어의 수를 몇개 사용할 것인지를 의미한다. 나의 경우는 서버 내 CPU의 전체 코어 수에서 일부(3개)만 제외하고 모두 사용하게끔 처리하였다.
- include_dashboard: Ray를 실행하면 ray의 진행 상태를 나타내는 dashboard가 자동으로 생성된다. 나의 경우는 코드에서 진행 상태를 확인하게 처리하였기 때문에 False처리하였다.
이것으로 ray에 대한 기본 세팅은 완료된다.
문제 예제
여기서는 아래의 문제 상황을 먼저 가정한다.
참고로 회사에서 실제로 겪었던 문제여서 문제 정의가 꽤 복잡하긴 하다.
카카오의 친구들은 부동산 매물 분석 프로젝트를 진행하고 있다.
어피치는 부동산 사이트 매물들을 크롤링해 DB에 적재하는 크롤링 봇을 개발하였다.
한편 부동산 사이트는 여러 중개업자들이 매물을 올릴 수 있어서 동일한 상품에 대한 중복 매물이 발생하게 된다.
어피치가 분석한 결과, 최초로 올라온 매물은 대표 매물로 설정이 되고 나머지 중복된 매물들은 해당 대표 매물의 코드(id)를 가진다.
정리하면 각 매물은 매물 코드(code)와 대표 매물 코드(rep_code), 그리고 기타 부동산 정보들을 가진다.
1. 매물 코드는 각 매물마다의 고유한 id로 매물마다 고유한 값을 가진다.
2. 대표 매물 코드는 해당 매물이 대표 매물인 경우와 아닌 경우로 아래와 같이 분류된다.
* 대표 매물인 경우: 대표 매물 코드 값이 NA를 가지게 됨
* 대표 매물이 아닌 경우: 대표 매물의 매물 코드 값을 가지게 됨
3. 중복 매물들은 대표 매물을 제외한 모든 매물들의 대표 매물 코드 값이 같아야 함. 대표 매물 코드 값은 대표 매물의 매물 코드 값임
한편 팀원 프로도는 데이터에서 이상한 점을 발견하였다.
중복 매물들이 하나의 대표 매물 코드를 가지지 않고 있었다. 즉, 특정 매물의 대표 매물로 설정된 매물이 또 다른 대표 매물 코드를 가지고 있는 것이다.
프로도는 다음과 같이 추정하였다.
1. 부동산 사이트에서 대표 매물이 삭제된 경우, 다음 중복 매물이 대표 매물로 된다.
2. 이 경우, 이전에 적재된 매물들은 삭제된 매물을 대표 매물로 가르키고, 새로 크롤링 되는 데이터들은 다음 중복 매물을 대표 매물로 가르킨다.
프로도는 이 문제를 해결하기 위해 데이터 내 중복매물들은 모두 동일한 대표 매물 코드 값을 가지게끔 바꾸려고 한다. 이 떄 코드를 어떻게 짜야 효율적으로 대표매물코드를 변경할 수 있을까?
아래는 이 문제에 대한 데이터 예시이다.
| code | rep_code | price |
| A | NA | 500 |
| B | A | 500 |
| C | B | 500 |
| D | NA | 300 |
| E | C | 500 |
- 매물 A와 매물 D는 대표 매물이다.
- 매물 E, C, B는 각각 대표 매물로 C, B, A를 가르킨다. 즉, 세 매물 모두 같은 중복 매물이나 가르키고 있는 대표 매물이 다르게 된다.
이를 아래와 같이 바꾸는 코드를 작성하려고 한다.
| code | rep_code | price |
| A | A | 500 |
| B | A | 500 |
| C | A | 500 |
| D | D | 300 |
| E | A | 500 |
- 대표 매물의 경우, 본인의 매물 코드를 대표 매물 코드로 가진다.
- 중복 매물의 경우 하나의 대표 매물 코드만을 가진다.
이 문제를 해결하기 위해 Ray를 사용하지 않고 작성했던 Case 1 코드이다.
"""
Case 1. 기본 코드
"""
def chg_repcode(df, idx):
# observation representative code
code, rep_code = df.loc[idx]
# iterate while rep_code have the value
# If observation is missing, change code to rep_code, and make rep_code None for break iteration.
# else change code, rep_code to observation's values
while (pd.isnull(rep_code) == False):
obs = df.loc[df['code'] == rep_code].values
if len(obs) == 0: code, rep_code = rep_code, None
else: code, rep_code = obs[0]
return code
# change rep_code of each observation
for idx in df.index:
df.loc[idx, 'rep_code'] = chg_repcode(df, idx)코드 내용은 다음과 같다.
- 코드의 rep_code 가 null이거나 code와 rep_code 값이 같은 경우, 해당 매물은 대표 매물이다. 이 경우, 매물 코드를 그대로 return한다.
- 만약 rep_code 값이 있는 경우, 해당 rep_code의 매물을 찾고 아래 과정을 수행한다.
- DB 내에 대표 매물 정보가 있는 경우: 재귀 함수를 통해 함수를 반복해서 종단의 대표 매물을 찾는다.
- DB내에 대표 매물 정보가 없는 경우: 본인을 rep_code로 설정한다.
- 이 함수를 데이터 내 모든 매물들에 대해 수행한다.
아래에서 이 코드를 Ray로 변경한 경우를 소개하고, Ray 도입 전후 시간을 비교해보자.
Ray 를 이용한 코드 작성
ray의 기본 사용법은 아래와 같다.
- ray는 함수에 ray함수라는 표식을 붙여준다. 이는 함수 선언 전에 데코레이터(@)를 이용해 나타낸다.
- ray 함수는 함수명 뒤 .remote() 를 통해 호출할 수 있다.
- 똑같은 데이터와 변수를 각 쓰레드에 다시 분배하는 것은 비효율적이다. 따라서 자주 사용하는 변수는 공용으로 사용할 수 있게 메모리 하나에 올리는 것이 효율적이다. 이를 위해 ray.put() 을 이용할 수 있다.
- 함수의 결과는 ray.get() 함수로 받을 수 있다.
이를 이용해 아래의 Case 2. 코드를 작성하였다.
"""
Case 2. ray.get()을 이용한 코드 병렬화
"""
@ray.remote
def chg_repcode(df, idx):
# observation representative code
code, rep_code = df.loc[idx]
# iterate while rep_code have the value
# If observation is missing, change code to rep_code, and make rep_code None for break iteration.
# else change code, rep_code to observation's values
while (pd.isnull(rep_code) == False):
obs = df.loc[df['code'] == rep_code].values
if len(obs) == 0: code, rep_code = rep_code, None
else: code, rep_code = obs[0]
return code
# save dataframe to shared memory
df_ref = ray.put(df.loc[:, ['code', 'rep_code']])
# Change rep_code using ray
df['rep_code'] =ray.get([chg_repcode.remote(df_ref, idx) for idx in df.index])코드는 내용은 다음과 같다.
- 기존 함수 코드를 데코레이터(@)를 이용해 ray함수로 설정하였다.
- 매물 데이터는 함수에서 반복해서 사용되기 때문에 ray.put() 함수로 메모리 하나에 로드하였다.
- 결과를 ray.get() 함수를 통해 가져온다.
Case 2.는 ray를 통해 각 코어에 여러 쓰레드를 분배한다.
하지만 Case 2. 의 경우, 코드 결과는 아래 그림처럼 작업이 모두 종료된 후에 처리해 출력되기 때문에 비효율적이다.
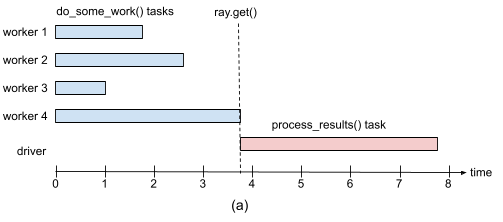
이 경우, ray.wait()을 통해 각 작업이 종료될 때마다 결과를 가져오는 방법을 이용할 수도 있다.
즉, 쓰레드가 끝난 경우, 그 결과를 바로바로 가져오는 방식으로 아래 그림과 같다.
각 일들이 끝날 때마다 결과를 바로 가져와서 처리하기 때문에 처리 시간이 훨씬 단축된다.
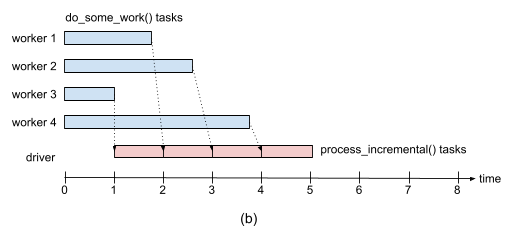
관련한 자세한 설명은 이 링크를 참고할 수 있다.
ray.wait()를 이용한 코드는 Case 3.과 같다.
"""
Case 3. ray.wait()을 이용한 코드 병렬화
"""
@ray.remote
def chg_repcode(df, idx):
# observation representative code
code, rep_code = df.loc[idx]
# iterate while rep_code have the value
# If observation is missing, change code to rep_code, and make rep_code None for break iteration.
# else change code, rep_code to observation's values
while (pd.isnull(rep_code) == False):
obs = df.loc[df['code'] == rep_code].values
if len(obs) == 0: code, rep_code = rep_code, None
else: code, rep_code = obs[0]
return idx, code
df_ref = ray.put(df.loc[:, ['code', 'rep_code']])
working_list =[chg_repcode.remote(df_ref, idx) for idx in df.index]
while len(working_list):
done_id, working_list = ray.wait(working_list)
idx, rep_code = ray.get(done_id[0])
df.loc[idx, 'rep_code'] = rep_code코드 내용은 아래과 같다.
- 기존 ray.get()에 넣었던 리스트를 working_list로 명명함
- ray.wait() 함수는 working_list 내의 일 n개가 끝날 때 까지 기다림. 일이 끝난 경우, done_id가 끝난 일 n개를 리스트로 가지고, working_list는 n개의 일을 제외한 나머지 일들을 가지고 있음.
- ray.wait()는 디폴트로 1개의 끝난 일을 내뱉게끔 설정돼 있음. 따라서 위 코드의 done_id 리스트에는 끝난 1개의 일을 가져오게 작성됨
- working_list 내에 남아 있는 일이 없을 때까지 해당 프로세스를 반복함
ray 사용을 마친 후에는 항상 ray를 종료해주는 것이 좋다. 종료 코드는 아래와 같다.
# Turn off ray
ray.shutdown()
Ray 사용 케이스별 성능 비교
위와 같이 Ray를 사용하지 않았을 때(Case 1)와 Ray를 사용한 경우(Case 2, Case 3)로 나누어 코드를 작성해보았다.
그리고 실제로 성능이 얼마나 차이가 나는지를 측정하였다.
측정된 시간은 IPython의 magic command인 %%time을 이용해서 측정된 Wall time이다.
| Case 1 | Case 2 | Case 3 | |
| 시간 | 123분 | 147분 | 135분 |
결과는 꽤 의아했는데, ray를 도입한 후 성능이 오히려 하락하였다.
꽤 시간이 오래걸리던 작업이라 Ray를 도입하였는데 왜 성능이 오히려 좋아지지 않았을까?
찾아보니 오버헤드(Overhead)가 발생했을 가능성이 컸다.
왜 나의 경우는 성능이 향상되지 않았는가?
그렇다면 병렬처리를 해서 CPU가 여러 일을 동시에 처리하게끔 했는데 왜 성능은 오히려 나빠졌을까?
일반적인 코드와 달리, 병렬 처리는 각 스레드를 CPU 코어들에 맡기고, 그 결과를 다시 모으는 과정을 수행해야 한다.
병렬 처리로 인해 추가적인 시간 비용이 소요되는 것이다.
이 때, 병렬처리되는 각 쓰레드의 실행 시간이 길지 않다고 하면, 추가적인 시간 비용이 병렬 처리로 인해 감소되는 시간보다 큰 것이다.
사실 예시에서 각 매물의 대표 매물 코드를 변경하는 시간은 매우 짧은 시간안에 처리된다.
하지만 데이터의 양이 방대해서 이를 처리하는데 시간이 오래 걸리는 것이다.
즉, 나는 병렬처리로 인해 발생하는 추가적인 시간 소요는 생각하지 않고 병렬처리의 장점만을 고려했었다.
오버헤드를 간과한 것이다.
결론
시간이 오래 걸리는 이유가 단순히 반복량이 많아서인지, 아니면 함수 실행의 시간이 오래걸리는지 고민하고 ray를 도입해야 한다.
반복되는 각 작업이 복잡하고 시간이 오래 걸릴 때는 Ray를 통한 병렬 처리가 효율적일 수 있다.
하지만 각 작업의 Task가 단순해서 연산량이 적은데, 병렬처리를 하는 경우에는 오히려 오버헤드가 발생할 수 있다.
참조
- ray 첫 사용자를 위한 팁: https://docs.ray.io/en/latest/ray-core/tips-for-first-time.html
- 병렬처리 오버헤드와 관련된 글: https://velog.io/@gwak2837/멀티코어-컴퓨팅-4주차
'Programming > Python' 카테고리의 다른 글
| [Python] upsert문 간접 구현하기 (0) | 2024.02.05 |
|---|---|
| [Python] json 출력 포맷 설정하기 (0) | 2023.12.19 |
| [Python] pip freeze 시, 버전명이 '@ file:///' 로 뜨는 문제 (0) | 2023.06.16 |
| [Python] 하버사인 (haversine)으로 위경도가 주어진 두 지점 거리 구하기 (0) | 2022.10.12 |
| [Python] functools의 partial 함수 알아보기 (2) | 2022.09.25 |